
Selenium Webdriver for Automation Testing using OCR Technology with simple CAPTCHA
As we all know, automation testing is growing today, and certainly, in the future, the demand for automation testers will increase. Because of that, businesses have been looking for resources for the future to apply automated testing for software testing. When it comes to automated testing, we cannot fail to mention selenium – a software-testing framework, and in particular the selenium web driver – a component of the Selenium toolkit, which enables automation of testing with the use of a programming language for maximum flexibility and expansion in the development of the test. With selenium web driver, we will see the advantages of its: it is an open source program, supports many programming languages, operating systems, browsers, and community support. However, besides that, they have many disadvantages such as not supported on Windows Application, no support functionality of extracting text from an image, no integration feature for Test Management Tool.

In this article, we will solve one problem of WebDriver as “it does not support the functionality of extracting text from an image” (at least as of now) by using ORC (Optical Character Recognition) technology. This also, solving a problem when a team approached me looking for a solution to extract text from an image (simple CAPTCHA) displayed on a web page and verify it’s contents as part of Selenium tests. This post will explain the solution using Tesseract, Tess4J along with Selenium for checking text displayed on images.
First, we have to understand the basic terms used in this post;
What is a CAPTCHA
CAPTCHA stands for Completely Automated Public Turing test to tell Computers and Humans Apart. As the acronym suggests, it is a test used to determine whether the user is human or not. A typical captcha consists of a distorted test, which a computer program cannot interpret but a human can (hopefully) still read.
In the test environment, when test a webpage that has a captcha, we have a few test approaches to deal with, such as.
- Either ask developer team for a workaround, like configure CAPTCHA in the test environment in such a way it will always accept 1 specific value.
- Ask the developer to disable the CAPTCHA module completely in the testing environment.
- If your team is using a custom CAPTCHA module, you can ask the developer to generate an API of CAPTCHA generation for the testing environment that can export the captcha to a normal text.
- Use a whitelisted IP, put the IP address of the tester into a valid IP list to access the system test without entering the CAPTCHA (bypass).
Recommendation: With the CAPTCHA module that it is possible to identify images to bypass, This CAPTCHA module should not be used in the system. In this post, we will use a simple captcha module to demonstrate the ability to extract the text from an image only. In your project, this method can be used effectively with Selenium for reading text from images along with English; it also supports native languages such as Turkish, Spanish, Hindi, Swedish etc… This has a typical architecture where we can feed the train data for image recognition.
What is an OCR
OCR – Optical Character Recognition – A program designed to convert a handwritten image or text into a digital document… Popular open source OCR tools are Tesseract, GOCR, ASPRISE, and Ocrad. We will use Tesseract for this tutorial, one of the few best open source for optical character recognition libraries today.
Tesseract is an open source OCR engine for various operating systems. It’s considered one of the most accurate OCR engines currently available, with the precision depending on the clearness of the image. Google has sponsored its development since 2006.
For programmers, Tesseract APIs can be used to build their applications. The library is called Labtesseract and is provided for C / C ++. In the case of using another language, the corresponding support package must be used. In this article we use the Java language, so we import the tess4j package for Java.
Tess4j is a Java wrapper that helps you use Tesseract-OCR engine to convert images to the accepted format from java. The library provides optical character recognition (OCR) support for:
- TIFF, JPEG, GIF, PNG, and BMP image formats
- Multi-page TIFF images
- PDF document format
Here we will show you our demo, This is a sample page – a SuiteCRM system with a simple captcha, we will extract the text from the image, and execute the test case “Verify that the user can log in successfully with captcha”.
The Process of integrating Tesseract OCR with java project is as below:
Step1:
We need a JNA (Java Native Access) wrapper to use tesseract in our java project. We can use tess4j for this. It can be downloaded from here http://tess4j.sourceforge.net/
Step2:
Now extract the contents of the tess4j archive to workspace location.
Step 3:
Download eng.traineddata for breaking Captchas with English (trained data is available for other languages as well) at https://github.com/tesseract-ocr/tessdata
Step 4:
Place tessdata at the project’s root directory.
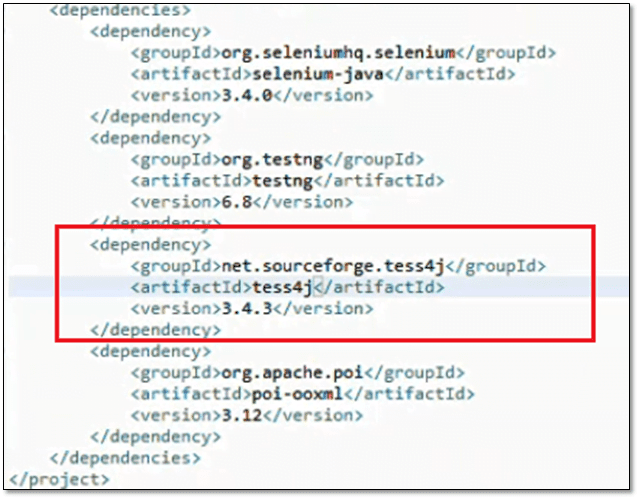
Step 5: Update POM Dependency
We are using Maven for this project, the scripts are written in the Java programming language on the Eclipse IDE using the TestNG Framework and the Selenium Webdriver library, as well as the Tesseract OCR library, we added Tess4j dependency to our pom.xml as below:
<dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>3.4.3</version> </dependency>
In this case, we will check the extracted text from the image then enter the newly captured value into the captcha textbox and enter the username and password, then we verify the results that user can log in the page with a captcha.
To check the text on the image, we will capture the image of a WebElement as the code below.
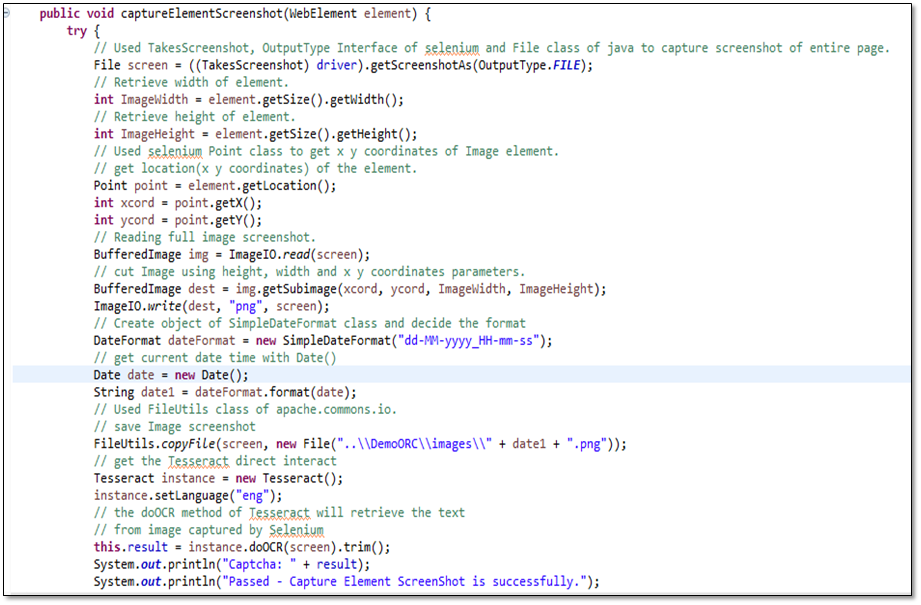
Then the
captured image is sent to doOCR() method of Tesseract instance to retrieve the
text, so we can get the text to fill.
With TesseractORC, image testing is no longer a problem with Selenium WebDriver.




